Stanford CS25: V1 I Self Attention and Non-parametric transformers (NPTs)

Non-Parametric Transformers | Paper explainedПодробнее

Stanford CS25: V1 I Audio Research: Transformers for Applications in Audio, Speech, MusicПодробнее

Stanford CS25: V1 I Transformers United: DL Models that have revolutionized NLP, CV, RLПодробнее

Stanford CS25: V2 I Introduction to Transformers w/ Andrej KarpathyПодробнее

What are Transformers (Machine Learning Model)?Подробнее

Stanford CS224N NLP with Deep Learning | 2023 | Lecture 8 - Self-Attention and TransformersПодробнее

Transformers, explained: Understand the model behind GPT, BERT, and T5Подробнее

Stanford CS25: V1 I Mixture of Experts (MoE) paradigm and the Switch TransformerПодробнее

Cross Attention vs Self AttentionПодробнее

Stanford CS25: V1 I Transformer Circuits, Induction Heads, In-Context LearningПодробнее

Stanford CS25: V1 I Transformers in Vision: Tackling problems in Computer VisionПодробнее

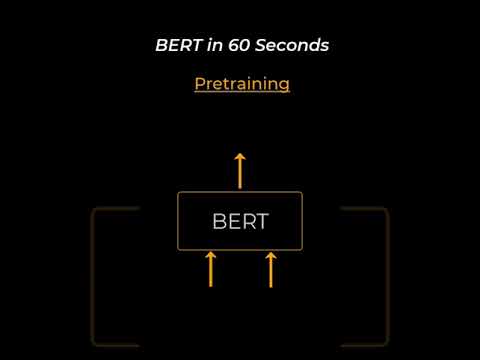
BERT Networks in 60 secondsПодробнее