Transformer Architecture part 2 - Explained Self Attention and Multi Head Attention
Transformer Architecture Part 2 Explaining Self Attention and Multi Head AttentionПодробнее

How do Transformers work: Explained through Encoder-Decoder #encoder #decoder #transformer #gpt #llmПодробнее

Master Multi-headed attention in Transformers | Part 6Подробнее

Complete Transformers For NLP Deep Learning One Shot With Handwritten NotesПодробнее

LLM Mastery 03: Transformer Attention All You NeedПодробнее

04.Understanding Transformers: Part 2 - Exploring the Transformer ArchitectureПодробнее

Transformers Architecture Explained | Key Components of Transformers Simplified #transformersПодробнее

Understanding Transformers & Attention: How ChatGPT Really Works! part2Подробнее

The Paper that changed everything! The Science Behind ChatGPT Fully ExplainedПодробнее

Building Transformer Attention Mechanism from Scratch: Step-by-Step Coding Guide, part 1Подробнее
[Technion ECE046211 Deep Learning W24] Tutorial 07 - Seq. - Part 2 - Attention and TransformersПодробнее
![[Technion ECE046211 Deep Learning W24] Tutorial 07 - Seq. - Part 2 - Attention and Transformers](https://img.youtube.com/vi/raKxOKm76Mk/0.jpg)
Transformers From Scratch - Part 1 | Positional Encoding, Attention, Layer NormalizationПодробнее
Attention Is All You Need - Part 2: Introduction to Multi-Head & decoding the mathematics behind.Подробнее
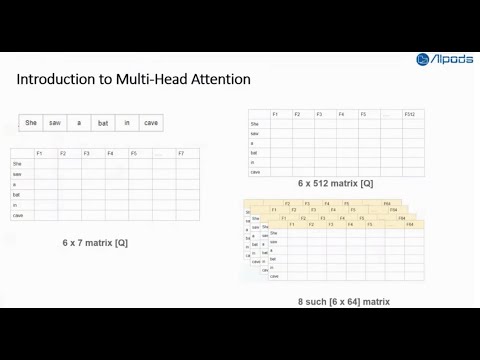
Transformers explained | The architecture behind LLMsПодробнее

Coding a Multimodal (Vision) Language Model from scratch in PyTorch with full explanationПодробнее
Demystifying Transformers: A Visual Guide to Multi-Head Self-Attention | Quick & Easy Tutorial!Подробнее

Attention in transformers, step-by-step | DL6Подробнее
Multi-Head Attention Mechanism and Positional Encodings in Transformers Explained | LLMs | GenAIПодробнее

Transformers (how LLMs work) explained visually | DL5Подробнее

What is Self Attention | Transformers Part 2 | CampusXПодробнее
