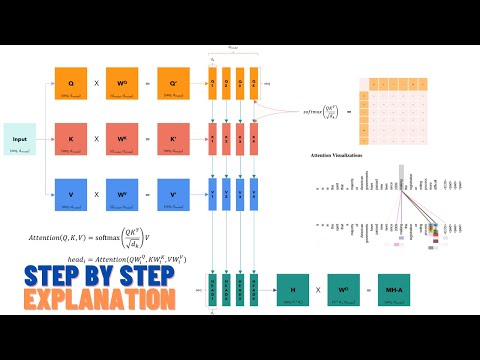
Coding a Transformer from scratch on PyTorch, with full explanation, training and inference.

Coding a Multimodal (Vision) Language Model from scratch in PyTorch with full explanationПодробнее
Coding Transformer From Scratch With Pytorch in Hindi Urdu || Training | Inference || ExplanationПодробнее

Decoder-Only Transformer for Next Token Prediction: PyTorch Deep Learning TutorialПодробнее

How to Build an LLM from Scratch | An OverviewПодробнее

[ 100k Special ] Transformers: Zero to HeroПодробнее
![[ 100k Special ] Transformers: Zero to Hero](https://img.youtube.com/vi/rPFkX5fJdRY/0.jpg)
Coding Stable Diffusion from scratch in PyTorchПодробнее

Implement and Train ViT From Scratch for Image Recognition - PyTorchПодробнее

BERT explained: Training, Inference, BERT vs GPT/LLamA, Fine tuning, [CLS] tokenПодробнее
![BERT explained: Training, Inference, BERT vs GPT/LLamA, Fine tuning, [CLS] token](https://img.youtube.com/vi/90mGPxR2GgY/0.jpg)
Coding a ChatGPT Like Transformer From Scratch in PyTorchПодробнее

Getting Started with Pytorch 2.0 and Hugging Face Transformers - Philipp Schmid, Hugging FaceПодробнее

LoRA: Low-Rank Adaptation of Large Language Models - Explained visually + PyTorch code from scratchПодробнее

LLaMA explained: KV-Cache, Rotary Positional Embedding, RMS Norm, Grouped Query Attention, SwiGLUПодробнее

Create GPT Neural Network From Scratch in 40 Minute - #pytorch #transformers #machinelearningПодробнее
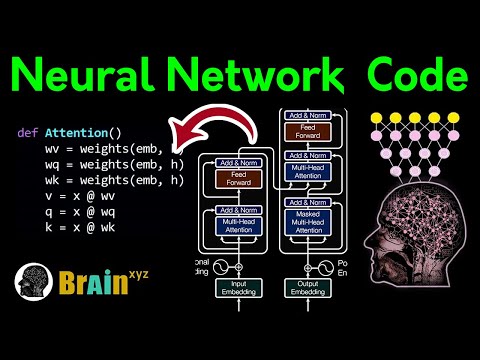
Coding LLaMA 2 from scratch in PyTorch - KV Cache, Grouped Query Attention, Rotary PE, RMSNormПодробнее

Building a GPT from scratch using PyTorch - dummyGPTПодробнее

Image Classification Using Vision Transformer | ViTsПодробнее
Create a Large Language Model from Scratch with Python – TutorialПодробнее

Deep Learning for Computer Vision with Python and TensorFlow – Complete CourseПодробнее

Attention is all you need (Transformer) - Model explanation (including math), Inference and TrainingПодробнее