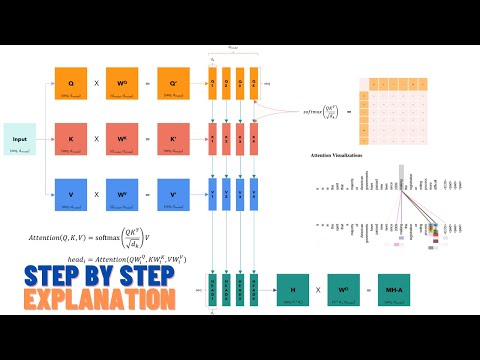
Transformer Architecture Explained: Part 1 - Embeddings & Positional Encoding
Transformer Architecture Explained: Part 1 - Embeddings & Positional EncodingПодробнее

RoPE Rotary Position Embedding to 100K context lengthПодробнее

Rotary Positional Embeddings (RoPE): Part 1Подробнее

Transformers From Scratch - Part 1 | Positional Encoding, Attention, Layer NormalizationПодробнее
BERT explained: Training, Inference, BERT vs GPT/LLamA, Fine tuning, [CLS] tokenПодробнее
![BERT explained: Training, Inference, BERT vs GPT/LLamA, Fine tuning, [CLS] token](https://img.youtube.com/vi/90mGPxR2GgY/0.jpg)
What are Transformer Models and how do they work?Подробнее

17. Transformers Explained Easily: Part 1 - Generative Music AIПодробнее

Attention in transformers, visually explained | DL6Подробнее
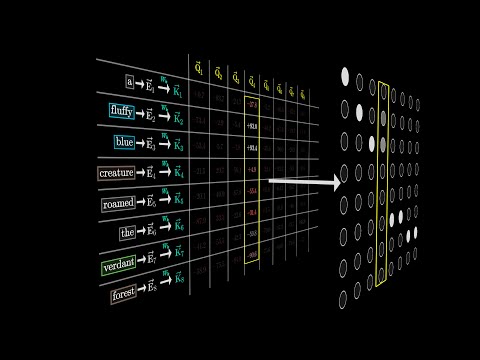
Transformer Code Walk-Through - Part -1Подробнее

Complete Course NLP Advanced - Part 1 | Transformers, LLMs, GenAI ProjectsПодробнее

Stanford XCS224U: NLU I Contextual Word Representations, Part 3: Positional Encoding I Spring 2023Подробнее

5 concepts in transformer neural networks (Part 1)Подробнее

LLaMA explained: KV-Cache, Rotary Positional Embedding, RMS Norm, Grouped Query Attention, SwiGLUПодробнее

Positional Encoding and Input Embedding in Transformers - Part 3Подробнее

Coding LLaMA 2 from scratch in PyTorch - KV Cache, Grouped Query Attention, Rotary PE, RMSNormПодробнее

Chapter 1: Transformer Models | Introduction Part: 1 | Urdu/HindiПодробнее

Transformer Neural Networks, ChatGPT's foundation, Clearly Explained!!!Подробнее
Decoder-Only Transformers, ChatGPTs specific Transformer, Clearly Explained!!!Подробнее

Word Embeddings & Positional Encoding in NLP Transformer model explained - Part 1Подробнее

Attention is all you need (Transformer) - Model explanation (including math), Inference and TrainingПодробнее